熟悉Java Stream API的同学可能知道可以利用parallelStream来实现并行操作,而Stream的并行操作依赖JDK1.7引入的Fork/Join框架,提供实现并行编程的一种方案。下面是Doug Lea对并行编程的描述:
(recursively) splitting them into subtasks that are solved in
parallel, waiting for them to complete, and then composing
results.
Fork/Join框架的主要设计思想是采用了类似分治算法( divide− and−conquer algorithms),将任务分割成许多小任务并行执行,最后合并计算结果,这比串行化执行效率提高不少。伪代码如下所示:
Result solve(Problem problem) {
if (problem is small)
directly solve problem
else {
split problem into independent parts
fork new subtasks to solve each part
join all subtasks
compose result from subresults
}
}
这里涉及到两个词,fork和join,在Doug Lea的论文中,有以下描述:
Fork:开启一个新的子任务进行计算
The fork operation starts a new parallel fork/join subtask.
Join: 导致当前任务等待直至被fork的线程计算完成
The join operation causes the current task not to proceed until the forked subtask has completed.
从fork/join的描述来看,就是利用递归不断的划分子任务,直至任务被划分的足够小,直接串行执行足够简单,没有问题。
测试和性能对比
我们通过计算1 ~ 100000000相加求和问题,来模拟fork/join并行执行,并通过与串行化for循环执行,利用线程池多线程并发执行 的时间对比,来推测fork/join的计算效率。
FOR串行
先考虑最简单的情况,直接利用for循环执行上面的计算任务,这是在单线程情况下来执行的,也就是串行执行,代码如下:
public class ForLoopCalculatorImpl implements Calculator {
@Override
public long sum(long[] numbers) {
long result = 0L;
for (int i = 0; i < numbers.length; i++) {
result += numbers[i];
}
return result;
}
}
这段代码相当简单,无需多言。
线程池并发
For循环执行时利用单线程来执行的,当计算任务较大时,我们可能会考虑使用多线程来处理计算任务,并且计算过程是异步的。首先考虑CPU核心数,将任务分割成与CPU核心数一样数量的子任务,避免CPU时间片的过度切换引起资源浪费。获取CPU核心数和初始化线程池的代码如下:
private static final int parallism = Runtime.getRuntime().availableProcessors();
private ExecutorService pool;
public ExecutorServiceCalculatorImpl() {
int corePoolSize = Math.max(2, Math.min(parallism - 1, 4));
int maximumPoolSize = parallism * 2 + 1;
int keepAliveTime = 30;
System.out.println(String.format("corePoolSize = %s, maximumPoolSize = %s", corePoolSize, maximumPoolSize));
BlockingQueue<Runnable> workQueue = new LinkedBlockingDeque<>();
// 线程的创建工厂
ThreadFactory threadFactory = new ThreadFactory() {
private final AtomicInteger mCount = new AtomicInteger(1);
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "AdvacnedAsyncTask #" + mCount.getAndIncrement());
}
};
// 线程池任务满载后采取的任务拒绝策略
RejectedExecutionHandler rejectHandler = new ThreadPoolExecutor.DiscardOldestPolicy();
pool = new ThreadPoolExecutor(corePoolSize,
maximumPoolSize,
keepAliveTime,
TimeUnit.SECONDS,
workQueue,
threadFactory,
rejectHandler);
}
上面的代码是使用ThreadPoolExecutor来创建线程池的,这样会更加了解线程池使用的各种细节。
接下来我们就需要使用线程池,根据CPU核心数来划分一定数量的子任务,然后将这些子任务交给线程池里面的线程去执行。此时注意任务的划分不一定是均匀的,因为最后一份任务可能比其他的多或者少,需要特别处理一下,代码如下:
@Override
public long sum(long[] numbers) {
List<Future<Long>> futures = new ArrayList<>();
// 把任务分解为 n 份,交给 n 个线程处理,
// 此时由于int类型丢失精度
int part = numbers.length / parallism;
for (int i = 0; i < parallism; i++) {
// 进行任务分配
int from = i * part;
// 最后一份任务可能不均匀,直接分配给最后一个线程
int to = (i == parallism - 1) ? numbers.length - 1 : (i + 1) * part - 1;
// 提交计算任务
futures.add(pool.submit(new SumTask(numbers, from, to)));
}
// 把每个线程的结果相加,得到最终结果
long total = 0L;
for (Future<Long> future : futures) {
try {
total += future.get();
} catch (Exception ignore) {}
}
pool.shutdown();
return total;
}
上面代码中涉及到一个计算任务SumTask,抽象出来用来计算从from 到 to 之间的数相加之和,代码如下:
private static class SumTask implements Callable<Long> {
private long[] numbers;
private int from;
private int to;
public SumTask(long[] numbers, int from, int to) {
this.numbers = numbers;
this.from = from;
this.to = to;
}
@Override
public Long call() throws Exception {
long total = 0;
for (int i = from; i <= to; i++) {
total += numbers[i];
}
return total;
}
}
看过上面的代码,我们主要是利用了线程池来并发来执行计算任务,同时利用了线程池异步的特性,从设计上来说比for循环串行执行要好,但由于涉及到CPU的时间片切换,执行耗时上可能会比串行执行要高。
Fokr/Join
写完线程池并发执行计算任务,如果让我们来设计并行执行任务的框架,可能会想到用线程池来做,既然Doug Lea写出了Fork/Join框架,肯定不是利用我们现在的方式来做,那么他是如何实现的呢?
Fork/Join框架抽象出了ForkJoinTask来代表要执行的计算任务,该类实现了Future接口,比Thread更加轻量级。不过我们通常不需要直接继承该类,Fork/Join框架给我们提供了两个抽象类供我们继承:
RecursiveTask:代表有返回值的计算任务RecursiveAction:代表没有返回值的任务
我们的计算任务有返回值,所以我们直接继承RecursiveTask就好了,代码如下:
public class SumTask extends RecursiveTask<Long> {
public static final int THRESHOLD = 2000000;
private long[] numbers;
private int start;
private int end;
public SumTask(long[] numbers, int start, int end) {
this.numbers = numbers;
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
// 判断问题规模
if ((end - start) <= THRESHOLD) {
long result = 0L;
for (int i = start; i <= end; i++) {
result += numbers[i];
}
return result;
}
// 将任务分割为多个小任务
int middle = (start + end) / 2;
SumTask taskLeft = new SumTask(numbers, start, middle);
SumTask taskRight = new SumTask(numbers, middle + 1, end);
invokeAll(taskLeft, taskRight);
long result = taskLeft.join() + taskRight.join();
return result;
}
}
我们需要重写RecursiveTask类的compute()方法,在该方法中进行任务的分割操作。和开始我们见到的伪代码类似,先判断任务规模(其实也是递归终止条件),相当于一个阈值,任务规模小于这个阈值,直接进行计算;大于这个阈值,将任务一份为二,这样递归下去,直至任务不可再分。注意这里我们采用invokeAll来进行任务分割,不过很多网上的例子采用的是如下写法:
// 分别对子任务调用fork():
subTask1.fork();
subTask2.fork();
在JDK官方例子中,这种写法是没有出现过的,也是不正确的,原因后面再分析。
Fork/Join框架提供了ForkJoinPool来执行我们分割好的任务,pool.invoke(task)来提交一个Fork/Join任务并发执行,然后获得异步执行的结果。代码如下:
public class ForkJoinCalculatorImpl implements Calculator {
private ForkJoinPool pool;
@Override
public long sum(long[] source) {
pool = new ForkJoinPool();
SumTask task = new SumTask(source, 0, source.length - 1);
return pool.invoke(task);
}
}
在利用Fork/Join计算任务时,可能会出现StackOverflowError,这是由于递归层数太深,导致超出JDK的设置,需要重新评估任务分割的程度或者调整大小。
如果任务分割不正确,还会抛出以下异常,需要关注:
java.lang.NoClassDefFoundError: Could not initialize class java.util.concurrent.locks.AbstractQueuedSynchronizer$Node
计算耗时(基础测试)
上面三种计算方式究竟计算效率怎么样呢?我们来写个测试类测试一把,代码如下:
long[] numbers = LongStream.rangeClosed(1L, 100000000L).toArray();
// 1 直接for循环
Calculator calculator = new ForLoopCalculatorImpl();
long currentTime1 = System.currentTimeMillis();
long result1 = calculator.sum(numbers);
long executedTime = System.currentTimeMillis() - currentTime1;
System.out.println("直接循环计算结果:" + result1 + ", 耗时:" + executedTime);
// 2 利用线程池
Calculator calculator2 = new ExecutorServiceCalculatorImpl();
long currentTime2 = System.currentTimeMillis();
long result2 = calculator2.sum(numbers);
long executedTime2 = System.currentTimeMillis() - currentTime2;
System.out.println("线程池计算结果:" + result2 + ", 耗时:" + executedTime2);
// 3 fork/join
Calculator calculator3 = new ForkJoinCalculatorImpl();
long currentTime3 = System.currentTimeMillis();
long result3 = calculator3.sum(numbers);
long executedTime3 = System.currentTimeMillis() - currentTime3;
System.out.println("Fork/Join计算结果:" + result3 + ", 耗时:" + executedTime3);
计算结果如下:
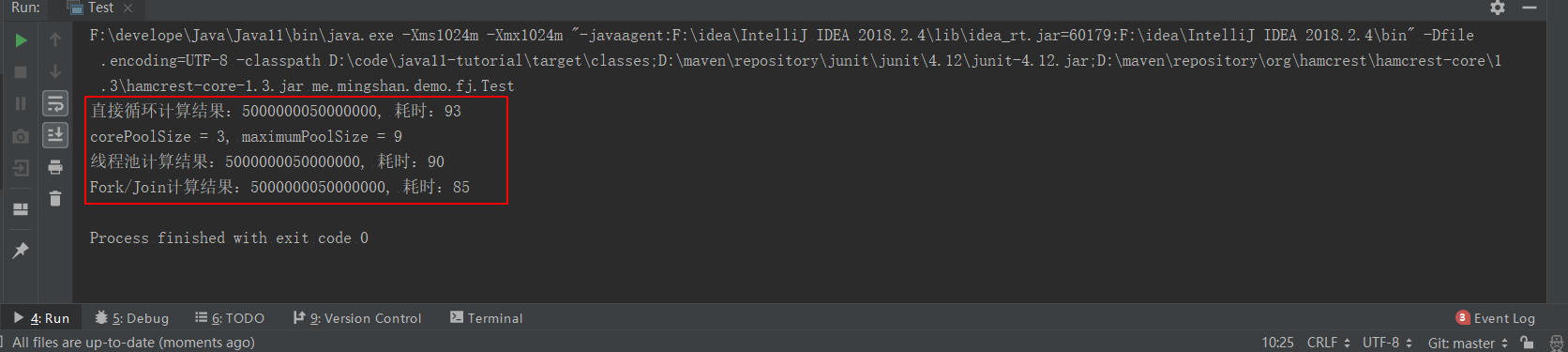
我用的是Window10操作系统,CPU i5 7代、4核心,跑的时候CPU飙到了100%,由于是计算密集型任务,需要CPU的全力参与,也无可厚非。。如下:
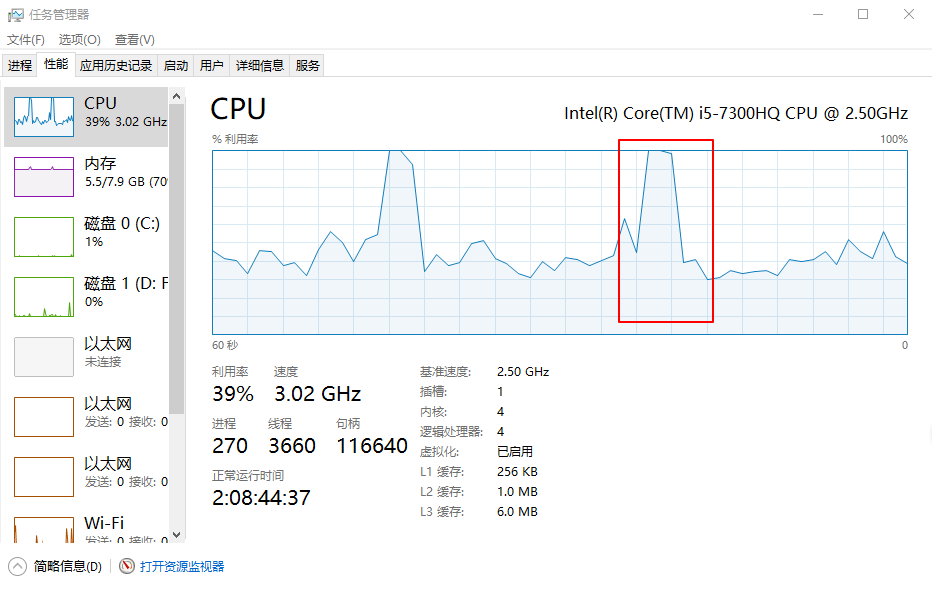
从上面的计算结果来看,Fork/Join耗时最少,线程池次之,直接For循环是耗时最多的,简直是难以置信啊,不过这个结果可能不稳定,至少也说明了Fork/Join在某些场景下比较优秀的事实(结论未必正确)。
基准测试(JMH)
上面我们是利用方法执行的开始与结束时间的差值来评估方法的执行性能,利用这种方式得出的结论往往是站不住脚的(不严谨),因为没有考虑到程序在运行时JVM所带来的影响,所以得出的结论未必可靠,我们也不能乱下结论。
那么有没有一个比较靠谱的性能测试框架呢?JMH(Java Microbenchmark Harness)是一个面向Java语言或JVM平台语言的性能基准测试框架,它针对的是纳秒级别、微秒级别、毫秒级别以及秒级别的性能测试。听上去是不是很叼?我们就用它来测试上面写的三个计算任务吧。
首先我们需要用@Benchmark来标识JMH基准测试的测试方法,用法和Junit的@Test类似,代码如下:
private static long[] numbers = LongStream.rangeClosed(1L, 100_000_000L).toArray();
@Benchmark
public void test1() {
// 1 直接for循环
Calculator calculator = new ForLoopCalculatorImpl();
calculator.sum(numbers);
}
@Benchmark
public void test2() {
// 2 利用线程池
Calculator calculator2 = new ExecutorServiceCalculatorImpl();
calculator2.sum(numbers);
}
@Benchmark
public void test3() {
// 3 fork/join
Calculator calculator3 = new ForkJoinCalculatorImpl();
calculator3.sum(numbers);
}
别忘了添加相关依赖哦,目前最新版本已是1.21,由于JMH性能测试是运行其提供的Main方法,需要添加maven相关插件配置运行Main方法,如下:
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>${jmh.version}</version>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>${jmh.version}</version>
<scope>provided</scope>
</dependency>
maven插件
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<finalName>java11-tutorial</finalName>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>org.openjdk.jmh.Main</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
接下来在该项目主目录下运行maven clean package进行编译打包,然后运行java -jar target/java11-tutorial.jar 直接执行测试,它的输出如下(重复的省略):
# JMH version: 1.21
# VM version: JDK 11, Java HotSpot(TM) 64-Bit Server VM, 11+28
# VM invoker: F:\develope\Java\Java11\bin\java.exe
# VM options: <none>
# Warmup: 5 iterations, 10 s each
# Measurement: 5 iterations, 10 s each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Throughput, ops/time
# Benchmark: me.mingshan.demo.fj.Test.test1
# Run progress: 0.00% complete, ETA 00:25:00
# Fork: 1 of 5
# Warmup Iteration 1: 11.702 ops/s
# Warmup Iteration 2: 11.902 ops/s
# Warmup Iteration 3: 11.014 ops/s
# Warmup Iteration 4: 10.663 ops/s
# Warmup Iteration 5: 11.611 ops/s
Iteration 1: 11.615 ops/s
Iteration 2: 11.981 ops/s
Iteration 3: 13.429 ops/s
Iteration 4: 12.363 ops/s
Iteration 5: 10.350 ops/s
...运行五次
Result "me.mingshan.demo.fj.Test.test1":
11.492 ±(99.9%) 0.864 ops/s [Average]
(min, avg, max) = (9.804, 11.492, 14.808), stdev = 1.154
CI (99.9%): [10.628, 12.356] (assumes normal distribution)
# JMH version: 1.21
# VM version: JDK 11, Java HotSpot(TM) 64-Bit Server VM, 11+28
# VM invoker: F:\develope\Java\Java11\bin\java.exe
# VM options: <none>
# Warmup: 5 iterations, 10 s each
# Measurement: 5 iterations, 10 s each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Throughput, ops/time
# Benchmark: me.mingshan.demo.fj.Test.test2
# Run progress: 33.33% complete, ETA 00:16:59
# Fork: 1 of 5
# Warmup Iteration 1: 17.420 ops/s
# Warmup Iteration 2: 15.220 ops/s
# Warmup Iteration 3: 15.497 ops/s
# Warmup Iteration 4: 14.617 ops/s
# Warmup Iteration 5: 17.724 ops/s
Iteration 1: 18.410 ops/s
Iteration 2: 18.326 ops/s
Iteration 3: 16.326 ops/s
Iteration 4: 15.471 ops/s
Iteration 5: 15.603 ops/s
...运行五次
Result "me.mingshan.demo.fj.Test.test2":
16.358 ±(99.9%) 1.549 ops/s [Average]
(min, avg, max) = (11.898, 16.358, 18.918), stdev = 2.068
CI (99.9%): [14.809, 17.907] (assumes normal distribution)
# JMH version: 1.21
# VM version: JDK 11, Java HotSpot(TM) 64-Bit Server VM, 11+28
# VM invoker: F:\develope\Java\Java11\bin\java.exe
# VM options: <none>
# Warmup: 5 iterations, 10 s each
# Measurement: 5 iterations, 10 s each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Throughput, ops/time
# Benchmark: me.mingshan.demo.fj.Test.test3
# Run progress: 66.67% complete, ETA 00:08:29
# Fork: 1 of 5
# Warmup Iteration 1: 14.169 ops/s
# Warmup Iteration 2: 14.925 ops/s
# Warmup Iteration 3: 14.652 ops/s
# Warmup Iteration 4: 14.448 ops/s
# Warmup Iteration 5: 14.090 ops/s
Iteration 1: 14.948 ops/s
Iteration 2: 15.234 ops/s
Iteration 3: 15.371 ops/s
Iteration 4: 15.451 ops/s
Iteration 5: 18.772 ops/s
...运行五次
Result "me.mingshan.demo.fj.Test.test3":
17.366 ±(99.9%) 0.902 ops/s [Average]
(min, avg, max) = (14.948, 17.366, 19.462), stdev = 1.204
CI (99.9%): [16.465, 18.268] (assumes normal distribution)
# Run complete. Total time: 00:25:27
REMEMBER: The numbers below are just data. To gain reusable insights, you need to follow up on
why the numbers are the way they are. Use profilers (see -prof, -lprof), design factorial
experiments, perform baseline and negative tests that provide experimental control, make sure
the benchmarking environment is safe on JVM/OS/HW level, ask for reviews from the domain experts.
Do not assume the numbers tell you what you want them to tell.
Benchmark Mode Cnt Score Error Units
Test.test1 thrpt 25 11.492 ± 0.864 ops/s
Test.test2 thrpt 25 16.358 ± 1.549 ops/s
Test.test3 thrpt 25 17.366 ± 0.902 ops/s
其中Fork:1 of 5指的是JMH会Fork出一个新的虚拟机,来运行基准测试,目的是获得一个相对干净的运行环境,每个 Fork 包含了 5 个预热迭代(warmup iteration,如# Warmup Iteration 1: 14.169 ops/s)和5个测试迭代(measurement iteration,如Iteration 5: 18.772 ops/s)。
每次迭代后面的数据代表本次迭代的吞吐量,即每秒运行的次数(ops/s),也就是一次操作调用了一次测试方法。
好了,我们直接来看性能测试结果吧,如下:
Benchmark Mode Cnt Score Error Units
Test.test1 thrpt 25 11.492 ± 0.864 ops/s
Test.test2 thrpt 25 16.358 ± 1.549 ops/s
Test.test3 thrpt 25 17.366 ± 0.902 ops/s
上面的输出便是本次基准测试的结果,主要关注Score和Error,Socre代表本次基准测试的平均吞吐量(每秒运行test*的次数),Error代表误差范围,所以。。。test1代表For循环串性执行,test2代表线程池并发执行,test3代表Fork/Join执行,结果很明显,Fork/Join每秒执行次数最多,线程池并发执行次之,For循环串性执行最少。
综合以上,我们可以小心翼翼地得出结论(怕被打。。),Fork/Join在计算密集型任务执行效率上是很好的,推荐大家使用。(完毕)
原理分析
目前先不分析,后面再写一遍文章。
参考: