WebMagic介绍
WebMagic是一个开源的Java垂直爬虫框架,目标是简化爬虫的开发流程,让开发者专注于逻辑功能的开发。最近项目有需求爬取某些网站的信息,考虑到WebMagic的爬虫实现十分精简和扩展性很高,所以爬虫模块就采用了WebMagic来爬取网站的一些信息。
WebMagic的结构分为Downloader、PageProcessor、Scheduler、Pipeline四大组件,并由Spider将它们彼此组织起来。这四大组件对应爬虫生命周期中的下载、处理、管理和持久化等功能。WebMagic的总体架构图如下:
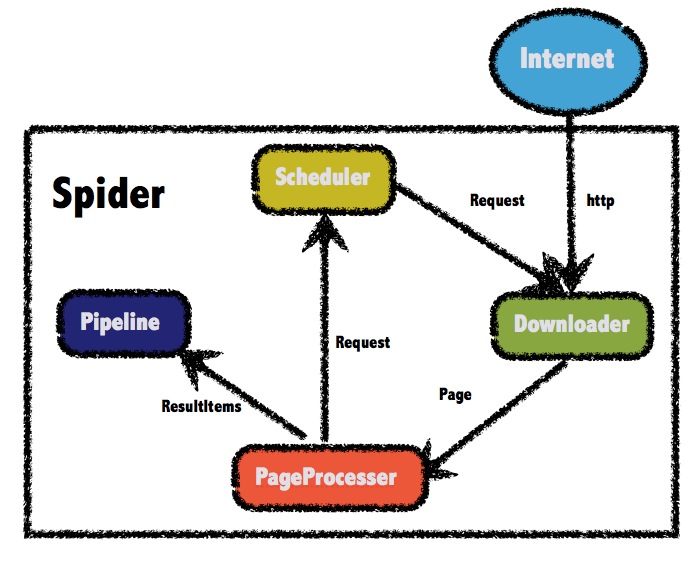
从上面的架构图中可以看出,我们在下载完页面后需要自己定义规则来抽取信息和发现链接,同时控制爬虫爬取深度,所以需要自定义PageProcessor来进行以上操作。而通过定制Pipeline,我们还可以实现保存结果到文件、数据库等一系列功能,所以我们可以根据自己的需求来自定义Pipeline。
爬虫实现
示例介绍
通过上面的分析,我们就可以来爬取特定页面的信息了。本次爬取的网站是http://www.zzuli.edu.cn/s/12/t/1006/p/22/i/13/list.htm,我们需要爬取的页面主要是列表+详情的基本页面组合,有一个列表页,这个列表页以分页的形式展现,我们可以遍历这些分页找到所有目标页面。我们要从通知的详细界面,来抓取通知的标题、内容、日期等信息,也要从列表页抓取的链接等信息,从而获取这个通知的所有文章。
列表页
列表页的格式如:
http://www.zzuli.edu.cn/s/12/t/1006/p/22/i/13/list.htm
其中i后面的13是可变的,根据上一页和下一页的切换来改变这一个数字,页面如下:

详细页
详细页的格式如下:
http://www.zzuli.edu.cn/s/12/t/1006/e8/ff/info190719.htm
http://www.zzuli.edu.cn/s/12/t/1006/e5/65/info189797.htm
通过观察这两个url,可以发现1006后面的都是可以变的,所以可以根据这个来写正则抽取链接。
详细页页面如下:

发现通知URL
在这个爬虫需求中,我们需要知道这些详细通知的URL,所以如何抽取这些URL显得很重要,事实也是如此,也是我们要实现爬虫的第一步。我们可以先考虑用以下正则表达式
http://www\\.zzuli\\.edu\\.cn/s/12/t/1006/\\w+/\\w+/info\\d+\\.htm
来过滤通知的详细界面,但这样未免太过宽泛,爬取效率也比较低,此时考虑到列表页中含有通知的详细界面的URL,所以我们必须从列表页中指定的区域获取URL。
在这里,我们使用xpath //table[@id=\"newslist\"]选中所有区域,再使用links()获取所有链接,最后再使用正则表达式http://www\\.zzuli\\.edu\\.cn/s/12/t/1006/\\w+/\\w+/info\\d+\\.htm, 对URL进行过滤,去掉一些其他无用的链接。于是,我们可以这样写:
page.addTargetRequests(page.getHtml().xpath("//table[@id=\"newslist\"]").links().regex(URL_POST).all());
同时,我们需要把所有找到的列表页也加到待下载的URL中去:
page.addTargetRequests(page.getHtml().links().regex(URL_LIST).all());
抽取内容
抽取页面所需要的信息对于爬虫应用来说是关键的一步,同时也是比较简单的,因为我们可以用xpath来解析html,定义好抽取表达式就可以了。
page.putField("title", page.getHtml().xpath("//h1[@class='arti-title']/text()"));
page.putField("content", page.getHtml().xpath("//div[@class='read']"));
page.putField("date",
page.getHtml().xpath("//div[@class='arti-metas']/table/tbody/tr/td[3]/span/text()").replace("日期:", ""));
列表页和详细页
我们可以定义几个常量来定义列表页和详细页的URL:
private static final String DOMAIN = "http://www\\.zzuli\\.edu\\.cn";
private static final String URL_LIST = DOMAIN + "/s/12/t/1006/p/22/i/\\d+/list\\.htm";
private static final String URL_POST = DOMAIN + "/s/12/t/1006/\\w+/\\w+/info\\d+\\.htm";
我们可以根据URL_LIST和URL_POST来区别列表页和详细页的抽取。
保存信息
我们可以自定义Pipeline来将抽取的结果保存在想要的地方,这里我直接将标题、内容、日期等信息封装为实体,然后放到List中,便于后续处理,代码如下:
/**
* 自定义Pipeline,用来处理爬到的数据
*
* @author mingshan
*
*/
public class NoticePipeline implements Pipeline {
public void process(ResultItems resultItems, Task task) {
Notice notice = null;
try {
notice = new Notice(resultItems.getAll());
notice.setLink(resultItems.getRequest().getUrl());
} catch (Exception e) {
return ;
}
NoticeList.addNotice(notice);
}
}
总结
通过以上的爬虫的实现,我们主要根据列表页来抽取所需要的通知详细页的URL,然后通过xpath来解析页面,获取特定的信息。如此简洁的逻辑和代码得益于WebMagic框架良好的封装,同时扩展性很强,推荐大家使用。